Restoration of diacritics can be seen as a special case of spelling correction. In particular, the same division on word-based methods and methods using the context is present. The methods that use the context are similar to those used in spelling correction. For a description of those methods see [Yar94a] and [Yar94b].
The word-based methods for the restoration of diacritics are also the basis for the context-based methods by providing them with choices. The techniques used in them are partially different from those used in spelling correction. In particular, if the word from a text is present in the lexicon, it does not mean that it is correct; all words that when deprived of diacritics give the word should be given.
We define a function strip that converts the letter with diacritics in the word being the argument of the function to the letters that have the same shape, but do not have diacritics. That function defines a relation:
![]()
The purpose of the word-based method for the restoration of diacritics
is to find all words that are in ![]() with the word in question. This
can be achieved by the use of statistical
techniques
measuring the frequencies of
sequences of letters in words (see [Dac97]), but the
standard technique is to use a lexicon. In particular, the lexicon in
form of a finite-state automaton offers the usual advantages: compact
representation and great speed of
processing. Figure 6.3 gives the algorithm for
finding all words in the lexicon that are in
with the word in question. This
can be achieved by the use of statistical
techniques
measuring the frequencies of
sequences of letters in words (see [Dac97]), but the
standard technique is to use a lexicon. In particular, the lexicon in
form of a finite-state automaton offers the usual advantages: compact
representation and great speed of
processing. Figure 6.3 gives the algorithm for
finding all words in the lexicon that are in ![]() with the given
word.
with the given
word.
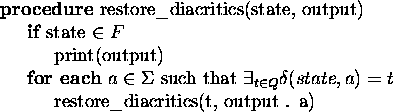
Figure 6.3: Restoration of diacritics with finite-state automata
The dot operator in fig. 6.3 represents concatenation. Note that it is also possible to use the same algorithm with the morphological dictionaries , implemented both with transducers and automata-acceptors. The corrections necessary for their adaptation are trivial.