Simple automata - acceptors can be used for morphological
analysis. They can provide faster analysis, but the range of languages
that can be described with such machines is more limited than in the
case of transducers. Also, special encoding techniques are necessary
for the contents of dictionaries (see section 3.2.2,
page  , for the instructions on how to prepare
data for a dictionary in form of an automaton-acceptor).
, for the instructions on how to prepare
data for a dictionary in form of an automaton-acceptor).
Note that the strings in a dictionary have an internal structure. They have two parts: the first is the inflected form of a word, the second - its annotations, describing e.g. the corresponding lexeme or morphological categories . Those parts are separated with an annotation separator . The analysis has two phases corresponding to those parts. The first phase is the recognition of the inflected forms. The second one treats annotations.
Annotations may contain lexemes. The lexemes are coded (see
section 3.2.2, page ) to
reduce the size of the dictionary. They must be decoded during the
analysis. The decoding consists of copying the inflected form without
a few letters from the end, as indicated by the code. The procedures
can be found in figure6.5.
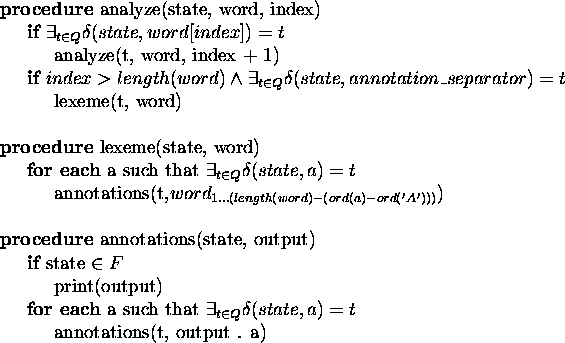
Figure 6.5: Morphological analysis with automata-acceptors
Note that it may be useful to introduce prefixes in the dictionary in the same way as in the analysis of unknown words. An additional code would say how many characters should be rejected from the beginning of the word to get a lexeme. This variation has not yet been implemented.