During the process of tag assignment, the word to be tagged is inverted, a word beginning marker appended at the end of the string, and subsequent transitions in the automaton starting from the start state are traversed if their labels match subsequent characters in the string. A state is reached where there are no matching transitions. If there are transitions in the state that have labels belonging to tags, labels from all paths in the automaton starting from those transitions and ending in final states are printed as tags. Otherwise, the same algorithm applies recursively to all states reached directly from that state.
The process of recognizing words and finding corresponding annotations can be decomposed into a few steps (see fig. 6.6).

Figure 6.6: Morphological analysis of unknown words
The steps described above involve recognition of the prefixes, and decoding the lexemes. If the purpose is to obtain only the lexemes, or only the categories, or if the language in question does not have prefixes (e.g. French), the algorithms above are simplified (appropriate procedures are scrapped. See fig. 6.7 for an example of guessing the categories of inflected forms.
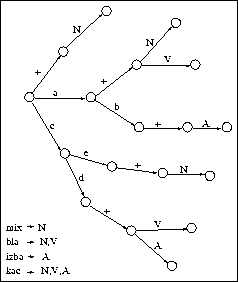
Figure 6.7: Guessing the categories of words. Prefixes and lexemes not
present
To evaluate how the rules described in sections 5.2.1,
5.2.2, and 5.2.3
(page  ) influence analyses of inflected forms,
unknown (i.e. not present in the lexicon) correct Polish words were
selected from a corpus. 405 words were chosen - all words that
started with ``b'' and were judged to be correct. Foreign words,
abbreviations, and misspellings were rejected. Also, a small percent
of words that fell into classes not yet in the lexicon (which is under
construction) were rejected as well. Table 6.1 shows the
results.
) influence analyses of inflected forms,
unknown (i.e. not present in the lexicon) correct Polish words were
selected from a corpus. 405 words were chosen - all words that
started with ``b'' and were judged to be correct. Foreign words,
abbreviations, and misspellings were rejected. Also, a small percent
of words that fell into classes not yet in the lexicon (which is under
construction) were rejected as well. Table 6.1 shows the
results.
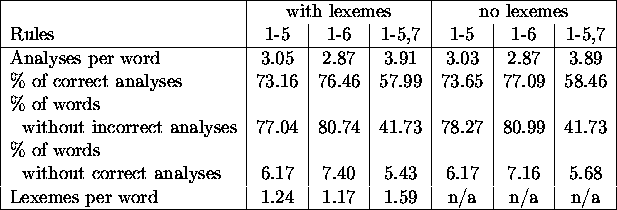
Table 6.1: Impact of rules on analyses
It seems that the rule R6 is best suited for tagging or as a preprocessor for a parser, while R7 is better for a lexicographer, as it can find some additional analyses.
The standard measures of the quality of guessing are:
We set apart each tenth of morphological data, and we constructed a guessing automaton out of the remaining nine tenths of data. Then we used the words from the separated part to measure the quality of guessing. Table 6.2 shows the results. Mikheev reported recall 95%, precision 85%, and recall 92%.

Table 6.2: Average quality of guessing for Polish morphological data
When comparing our method with that used by Mikheev we should take several circumstances into account: